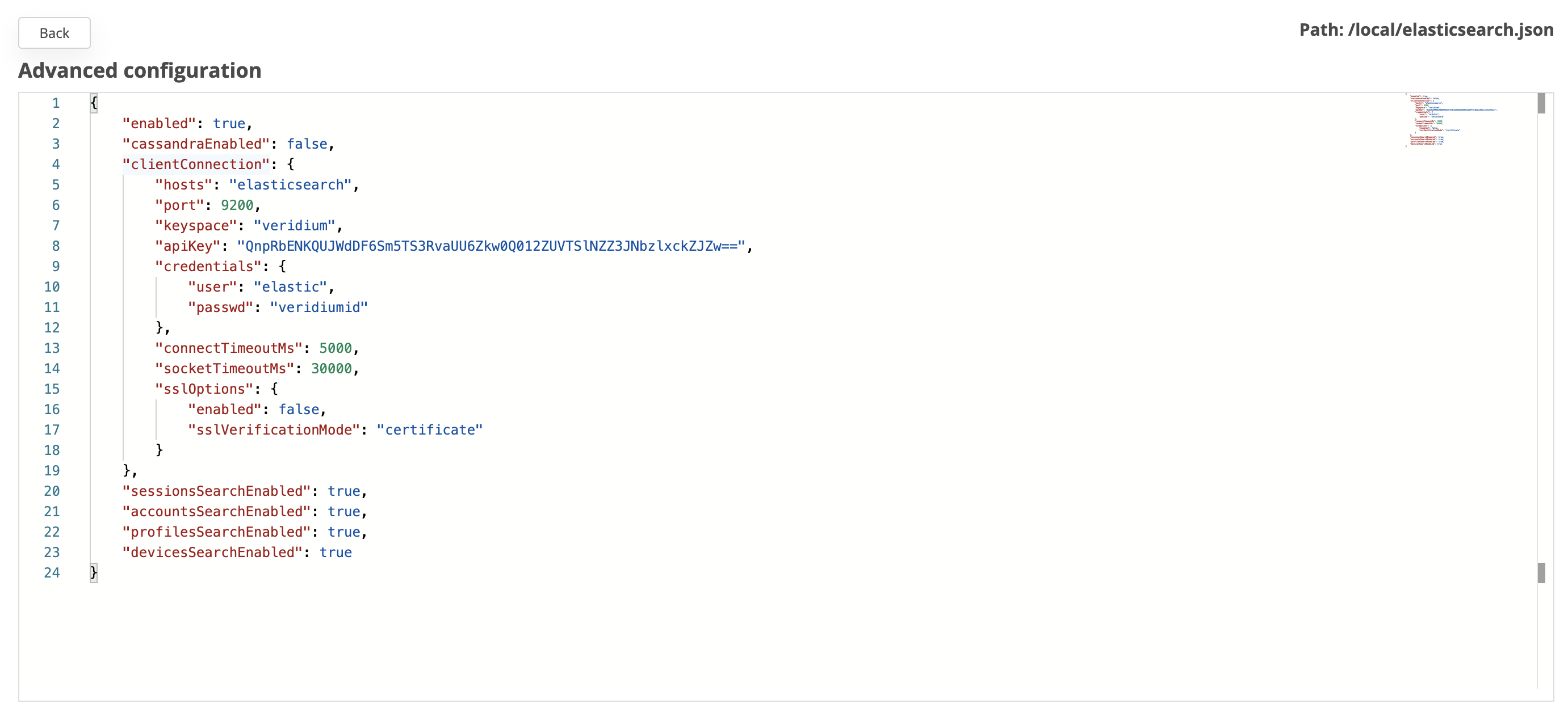
In this version, account, devices and identities data has been indexed in ElasticSearch together with their list of history events, for search purposes.
First of all, the esSettingsUpdate task has to be executed to create the needed indices and update mappings
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esSettingsUpdate
In order to migrate the data existing in Cassandra, the following commands can be used:
Devices
The first index that needs to be handled is the devices index
First of all, devices and their history need to be exported into multiple files with the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esDevicesMigration --export [--outDir=path-to-outdir] [--partitions=partitions] [--exportPageSize=exportPageSize]
The optional outDir parameter refer to the directory where the exported files will be created (default is “devices”), the partitions parameter refer to the number of files the devices are partitioned into (default 1000) and exportPageSize refer to the page size used to iterate over the tables in Cassandra (default 1000)
If there are batches of data that fail to be exported, they will be saved in a file on disk. In order to retry to export them, the following command can be used
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esDevicesMigration --retry-devices-export [--outDir=path-to-outdir] [--partitions=partitions] [--exportPageSize=exportPageSize]
In order to import the data exported in files in Elastic, the following command can be used:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esDevicesMigration --import [--inDir=path-to-indir]
Secondly, the devices_history index needs to be handled. This is done using the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esDevicesHistoryRebuild [--keyspace=keyspace] [--pageSize=pageSize] [--requestTimeoutMin=requestTimeoutMin] [connectionTimeoutMin=connectionTimeoutMin]
The keyspace parameter allows to specify a different keyspace (by default the one in zk is used) and the pageSize describes the page size used when iterating over the first index in Elastic (default 1000). The requestTimeoutMin and connectionTimeoutMin are the request and connection timeouts in minutes for ElasticSearch (default 5 and 1).
Accounts
The first index that needs to be handled is the accounts index
First of all, accounts adnd their history need to be exported into multiple files with the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esAccountsMigration --export [--outDir=path-to-outdir] [--partitions=partitions] [--exportPageSize=exportPageSize]
The optional outDir parameter refer to the directory where the exported files will be created (default is “accounts”), the partitions parameter refer to the number of files the accounts are partitioned into (default 1000) and exportPageSize refer to the page size used to iterate over the tables in Cassandra (default 1000)
If there are batches of data that fail to be exported, they will be saved in a file on disk. In order to retry to export them, the following command can be used
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esAccountsMigration --retry-accounts-export [--outDir=path-to-outdir] [--partitions=partitions] [--exportPageSize=exportPageSize]
In order to import the data exported in files in Elastic, the following command can be used:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esAccountsMigration --import [--inDir=path-to-indir]
Secondly, the accounts_history index needs to be handled. This is done using the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esAccountsHistoryRebuild [--keyspace=keyspace] [--pageSize=pageSize] [--requestTimeoutMin=requestTimeoutMin] [connectionTimeoutMin=connectionTimeoutMin]
The keyspace parameter allows to specify a different keyspace (by default the one in zk is used) and the pageSize describes the page size used when iterating over the first index in Elastic (default 1000). The requestTimeoutMin and connectionTimeoutMin are the request and connection timeouts in minutes for ElasticSearch (default 5 and 1).
Identities
Identities are migrated using the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esProfilesMigration [--exportPageSize=exportPageSize] [--taskSubmitAttempts=taskSubmitAttempts]
exportPageSize refers to the page size used to iterate over the entries in Elastic (default 100), taskSubmitAttempts refers to the number of retries per each batch (default 5).
If there are batches of data that fail to be exported, they will be saved in a file on disk. In order to retry to export them, the following command can be used
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esProfilesMigration --retry-profiles
Action Logs
Identities are migrated using the following command:
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esActionLogsMigration [--exportPageSize=exportPageSize] [--taskSubmitAttempts=taskSubmitAttempts]
exportPageSize refers to the page size used to iterate over the entries in Elastic (default 100), taskSubmitAttempts refers to the number of retries per each batch (default 5).
If there are batches of data that fail to be exported, they will be saved in a file on disk. In order to retry to export them, the following command can be used
java -DZKProperties=${PROJECT_DIR}/configs/zkConfigFiles/zookeeper.properties \
-Dspring.profiles.active=cassandra \
-Dlog4j.configuration=file:${PROJECT_DIR}/projects/standalonerunner/src/main/resources/log4j2.xml \
-jar persistence-migration-fat.jar esActionLogsMigration --retry-action-logs
Other configs
In order for new data to be saved in elastic, make sure that elasticsearch is enabled in elasticsearch.json. The four flags at the bottom can be used to control whether lucene searches are performed in cassandra or in elastic.