
-
check status, by running command:
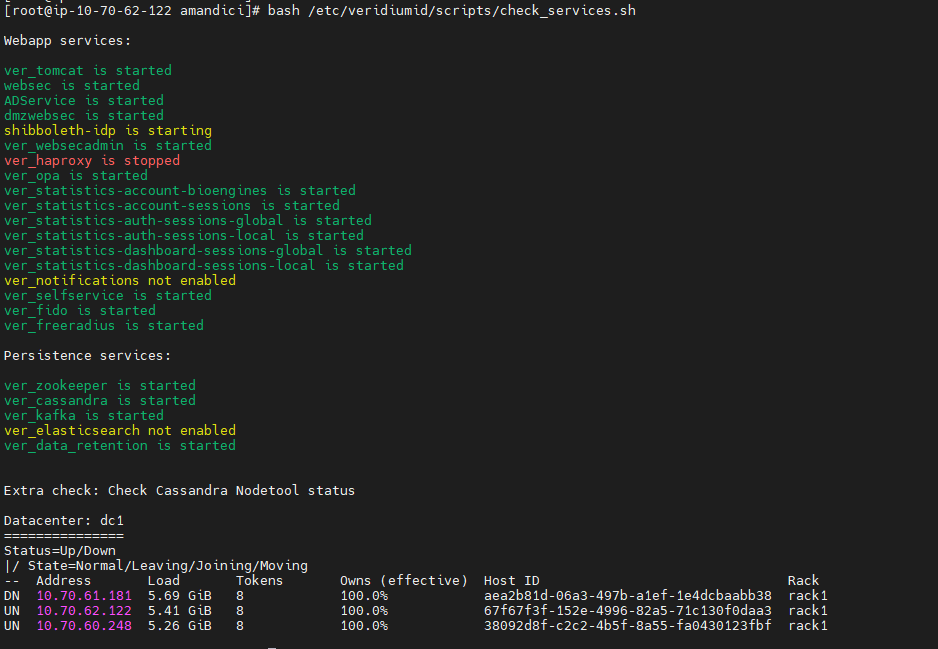
bash /etc/veridiumid/scripts/check_services.sh
-
the status of each process are self explanatory - “is starting”, “is stopped”, “not enabled”, “is started”, “is not present on this node”
-
Cassandra in this example is a 3 node cluster.
-
first node has status DN - Down Normal
-
the next 2 nodes are UN - UP Normal
-
-
Normally, all 3 nodes should have status UN.
-
If the script throws errors, it means that it can not connect to Cassandra on this specific server.
2. Disk: check if there is available space on the disk. It might be that Cassandra it remained out of space during some maintenance operations. The disk occupation for Cassandra should be less than 75% at any time.
To be more precise, it should be free on each node the double size of the database (one time it needs for operation maintenance and one time for backup). The size of Cassandra is shown in the prinscreen as Load (5.69gb).
df -h
3. Memory:
There should be at least 1Gb of memory free on cassandra servers. To check this, run below command. In the exampke there are 11404Mb free.
free -m

4. Backup and maintenance
Backup and maintenance are running once per week per each server. They are running under root account, using the following scripts:
## cassandra repair cluster for inconsistencies
bash /opt/veridiumid/cassandra/conf/cassandra_maintenance.sh -c /opt/veridiumid/cassandra/conf/maintenance.conf
## cassandra compact each node, to reduse space and the number of tumbstones
bash /opt/veridiumid/cassandra/conf/cassandra_maintenance.sh -c /opt/veridiumid/cassandra/conf/maintenance.conf -k
## cassandra backup; in file /opt/veridiumid/backup/cassandra/cassandra_backup.conf there are kept the number of copies.
bash /opt/veridiumid/backup/cassandra/cassandra_backup.sh -c=/opt/veridiumid/backup/cassandra/cassandra_backup.conf
Backups are kept in this location:
/opt/veridiumid/backup/cassandra
The following logs should be monitored for Errors, to be sure that maintenance and backup jobs are finished successfully.
/var/log/veridiumid/cassandra/backup.log
/var/log/veridiumid/cassandra/maintenance.log
5. How to import a table from one environment to a different one:
1. take the cassandra backup from production and copy it to lab environment.
cassandra backups can be found here: /opt/veridiumid/backup/cassandra/
The tables that might be sincronzed should be:
- device_by_cert_uuid
- device
- identity
- account
- session_finished
- history
copy the following files from production backup to lab environemnt:
please fill in the correct date of the backup
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/device_by_cert_uuid-*/snapshots/*/*db
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/device-*/snapshots/*/*db
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/identity-*/snapshots/*/*db
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/account-*/snapshots/*/*db
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/session_finished-*/snapshots/*/*db
/opt/veridiumid/backup/cassandra/2023-05-31_13-26/*/veridium*/history-*/snapshots/*/*db
## if all files needs to be recovered, please go to backup location, where all files are listed
for var in `ls -1`; do table=`echo ${var%-*}`; cp ${var}/snapshots/*/*db /opt/veridiumid/cassandra/data/veridium/${table}-*/; done
2. ensure that there is sufficient space on lab environemnt to load data.
The files should be copy to these locations:
/opt/veridiumid/cassandra/data/veridium/device_by_cert_uuid*/
/opt/veridiumid/cassandra/data/veridium/device*/
/opt/veridiumid/cassandra/data/veridium/identity*/
/opt/veridiumid/cassandra/data/veridium/account*/
/opt/veridiumid/cassandra/data/veridium/session_finished*/
/opt/veridiumid/cassandra/data/veridium/history*/
3. assign proper permissions:
chown -R ver_cassandra.veridiumid /opt/veridiumid/cassandra/data/veridium/
4. load new data - for cassandra 4, this step is not needed.
#first increase memory parameters for loader
sed 's|256M|1024M|g' /opt/veridiumid/cassandra/bin/sstableloader
## and after load the data
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/device_by_cert_uuid-*/
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/device-*/
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/identity-*/
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/account-*/
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/session_finished-*/
/opt/veridiumid/cassandra/bin/sstableloader -f /opt/veridiumid/cassandra/conf/cassandra.yaml -d `hostname -I` -p 9042 /opt/veridiumid/cassandra/data/veridium/history-*/
6. How to restore data from one node, in one datacenter, if data is lost on that node or files are corrupted:
Procedure 1:
-
How restore is working, in case that data is lost on one node:
-
If the node is not a seeder node, it is sufficient to start cassandra. It will automatically join the cluster and bring only the necessary data, without multiplying it.
-
If the node is a seeder node, the Cassandra recommendation is the following:
-
Replace in cassandra.yaml on all nodes (including broken one), in seeder list, broken node with a good one.
-
Restart all nodes one by one.
-
start Cassandra on broken node. It will automatically bring the data.
-
It was also tested, to do replacement only on the broken node.
-
During this intervention, please comment in crontab the maintenance jobs for Cassandra.
-
-
This method is the easiest one even in case of Cassandra corruption on one node.
-
-
It was also tested to have only one node with data in the cluster and all the other nodes were added one by one, just by configuring seeder list to first node.
service ver_cassandra stop
rm -rf /opt/veridiumid/cassandra/data/*
##in case that this node, is a seeder node, modify /opt/veridiumid/cassandra/conf/cassandra.yaml to exclude this node from the seeder list and set another functional node as a seeder.
## start cassandra; the node will stay in UJ status until it brings all the data from other nodes
service ver_cassandra start
Procedure 2 - using repair mode:
### check available space on disk; there should be avaiable twice the size of the database.
df -h
## if there is not enought space, remove unfinished backups; also if there are corrupted files resulted during compression, it may be deleted also.
/opt/veridiumid/cassandra/bin/nodetool listsnapshots
/opt/veridiumid/cassandra/bin/nodetool clearsnapshot --all
/opt/veridiumid/cassandra/bin/nodetool clearsnapshot veridium
### speed up the compactions/repair processes; this will be available until restart
## to test more if these are really improving the speed; it was tested with 0 and also with doubled default values
##nodetool getcompactionthroughput; nodetool getstreamthroughput
##nodetool setcompactionthroughput 32; nodetool setstreamthroughput 400
##nodetool getcompactionthroughput; nodetool getstreamthroughput
## if a file is corrupted (for ex. from /opt/veridiumid/cassandra/data/veridium/session_finished), it can be deleted, because the replication factor is 3 and the data is also found on other nodes.
##this will bring all the data from the other nodes, to the current one, so the database will increase several times; this procedure will run first repair on all nodes in a datacenter and after that will bring the data
/opt/veridiumid/cassandra/bin/nodetool repair
/opt/veridiumid/cassandra/bin/nodetool repair -dc dc1
##it is necessary also to run compact, to the database will reduce size
/opt/veridiumid/cassandra/bin/nodetool compact
##running this command, it will trigger repair in one datacenter and also compact on each node
/opt/veridiumid/cassandra/bin/nodetool repair --full -dc dc1
##also it there is a second datacenter with all the data, the following command can be executed:
/opt/veridiumid/cassandra/bin/nodetool rebuild -dc dc1
##follow status, by running the following commands:
/opt/veridiumid/cassandra/bin/nodetool compactionstats
/opt/veridiumid/cassandra/bin/nodetool repair_admin list
/opt/veridiumid/cassandra/bin/nodetool netstats
7. How to remove one datacenter from existing cluster
## run nodetool status to get the nodes ID
/opt/veridiumid/cassandra/bin/nodetool status
## remove nodes from decomissioned datacenter
nodetool removenode c9dddee2-ce00-42f7-b9a4-82ea4b93a556
nodetool removenode 28387f14-3ed1-4436-9b2b-10020f7a4677
nodetool removenode 6b0aed18-bfa9-4900-97c4-b9a4c8291540
## connect to currenct datacenter, with cqlsh and set the proper network strategy, without the decommissioned datacenter;
##!!!!!!!!!! PLEASE SETUP PROPERLY THE DATACENTERNAME AND THE NUMBER OF NODES
ALTER KEYSPACE system_auth WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'dc1' : 3};
ALTER KEYSPACE system_traces WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'dc1' : 3};
ALTER KEYSPACE system_distributed WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'dc1' : 3};
ALTER KEYSPACE veridium WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'dc1' : 3};
## if it is decommisioned primary datacenter from installation, please modify cassandra.yaml in secondary datacenter -> seeds to have only the nodes that remain in the cluster; please remove, if necessary the decommisioned datacenter.
## restart nodes one by one
service ver_cassandra restart
## it is recommended to run repair in existing datacenter; if not, it will run during the weekend in crontab.
/opt/veridiumid/cassandra/bin/nodetool repair -dc dc1
8. Other useful commands:
## check the actual size of cassandra database on the disk
du -sh /opt/veridiumid/cassandra/data/
## check the actual size of each backup
du -sh /opt/veridiumid/backup/cassandra/20*
## in case of emergency, it can be removed one old backup, as in below example
#rm -rf /opt/veridiumid/backup/cassandra/2023-05-27_13-26
All below operations can be done online, without downtime, in case of an issue.
########## you can monitor what compaction are running on DB
/opt/veridiumid/cassandra/bin/nodetool compactionstats
############# deletes deleted data; maybe usefull when you want to clean data that was deleted recently.
/opt/veridiumid/cassandra/bin/nodetool garbagecollect veridium
############# rebuild index
/opt/veridiumid/cassandra/bin/nodetool rebuild_index veridium session_finished session_finished_index
############# operations on tables
/opt/veridiumid/cassandra/bin/nodetool repair -local veridium session_finished
/opt/veridiumid/cassandra/bin/nodetool compact veridium session_finished
######### show nodes in a cluster
/opt/veridiumid/cassandra/bin/nodetool describecluster
######## clear snashots
/opt/veridiumid/cassandra/bin/nodetool clearsnapshot veridium
######### get memory utilisation
/opt/veridiumid/cassandra/bin/nodetool info
In order to see a table description, to run a query in DB, the following command can be used:
/opt/veridiumid/cassandra/bin/cqlsh --cqlshrc=/opt/veridiumid/cassandra/conf/veridiumid_cqlshrc --ssl
use veridium;
expand on;
desc tables;
select * from identity limit 10;
-
In case of deleting Cassandra on a node from a datacenter in CDCR
# Reinstall cassandra
rpm -ivh veridiumid_apache-cassandra*
# Copy /opt/veridiumid/cassandra/conf directory from a different node in the same datacenter
cd /opt/veridiumid/cassandra/conf
tar zcvf cassandra_conf.tar.gz *
# Move archive to node with reinstalled cassandra
cd /opt/veridiumid/cassandra/conf
rm -rf *
mv ARCH_LOCATION/cassandra_conf.tar.gz .
tar xvf cassandra_conf.tar.gz
rm -f cassandra_conf.tar.gz
chown ver_cassandra:veridiumid -R *
# Change other nodes IP address with current nodes IP address in configuration files
sed -i "s|listen_address.*|listen_address: IP_ADDR|g" cassandra.yml
sed -i "s|rpc_address.*|rpc_address: IP_ADDR|g" cassandra.yml
sed -i "s|OTHER_NODES_IP_ADDR|IP_ADDR|g" veridiumid_cqlshrc
# Connect to another node from the cluster and remove node from cluster
/opt/veridiumid/cassandra/bin/nodetool status
# Example respone:
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.56.202.231 81.99 MiB 8 100.0% c29667ef-420b-4895-9026-c86b79573e65 rack1
UN 10.56.164.186 81.87 MiB 8 100.0% 231dfefc-d7df-46a5-9ba4-78403ec37822 rack1
UN 10.56.146.204 46.07 MiB 8 100.0% e108438e-5b53-4816-a6c3-c6c73ed84eed rack1
Datacenter: dc2
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN 10.56.214.46 75.21 MiB 8 100.0% 28eac4e5-9c23-4fac-be77-ea3bad6a8a29 rack1
UN 10.56.199.137 44.62 MiB 8 100.0% 2c85c848-71bd-462d-9876-e52952d03048 rack1
UN 10.56.246.226 43.91 MiB 8 100.0% bc660371-9eb6-46d9-9f62-d031c8635c07 rack1
# Get the host ID of the node that is DOWN (status DN)
/opt/veridiumid/cassandra/bin/nodetool removenode NODE_ID
# Connect to reinstalled node and start Cassandra
service ver_cassandra start
# Wait for node to join the cluster, you can use nodetool status to check the state
/opt/veridiumid/cassandra/bin/nodetool status
# After node is back in cluster copy data from other datacenter
/opt/veridiumid/cassandra/bin/nodetool rebuild -dc OTHER_DC_NAME
# After rebuild operation has been completed run a full repair on same node
/opt/veridiumid/cassandra/bin/nodetool repair --dc CURRENT_DC_NAME