Containers
This document we will detail VeridiumID server in K8S infrastructure.
Introduction
The deployment is managed by HELM charts, with the ability to deploy a full working cluster in about one hour. The docker images are in nexus and in ECR, which are the application version. Container orchestration engine (Kubernetes, OpenShift) downloads those images from ECR and constructs pods and deployments using them. The scaling and auto-balancing is managed by services and replica sets. A nginx server is set up as an ingress controller which redirects outside traffic to the services in cluster. Pods communicate with each other using clusterIP services (intra-cluster communication).
The main services of VID server are:
websec
adservice
shiboleth
dmz
websecadmin
notification
statistics
fido
selfservice
data-retention
opa
freeradius
Each of this webapps (except data-retention) are deployed once on webapp nodes and have a haproxy which balances traffic between them. Data-retention is the only service that is deployed on a persistence node. The persistence layer is represented by cassandra, elasticsearch, zookeeper, which are installed and configured on persistence nodes. .
Each service is separate and stays it on a single POD resource, as a separate microservice.
All the above micro-services with have assigned a deployment (with a replica-set) that will be managed by a Kubernetes/OpenShift service. The micro-service we expect traffic from outside the cluster will be created using NodePorts, otherwise they will be ClusterIPs. Another approach for this is using a Haproxy ingress controller. For this approach ALL micro-services will be ClusterIPs and Nginx will be a daemon-set deployment as a NodePort. He will redirect all incoming traffic to the services based on SNI or ports. Haproxy will manage also SSL termination and header manipulation. The persistence layer will be deployed as a stateful-sets using CRDs or non-CRDs resources, and have a ClusterIP service headless which will manage routing and access. This will not provide access from outside the cluster to the persistence layer. For debugging and administration purposes, port-forwarding or ssh login can be used directly on the desired pod.
A top overview on the Kubernetes/OpenShift cluster:
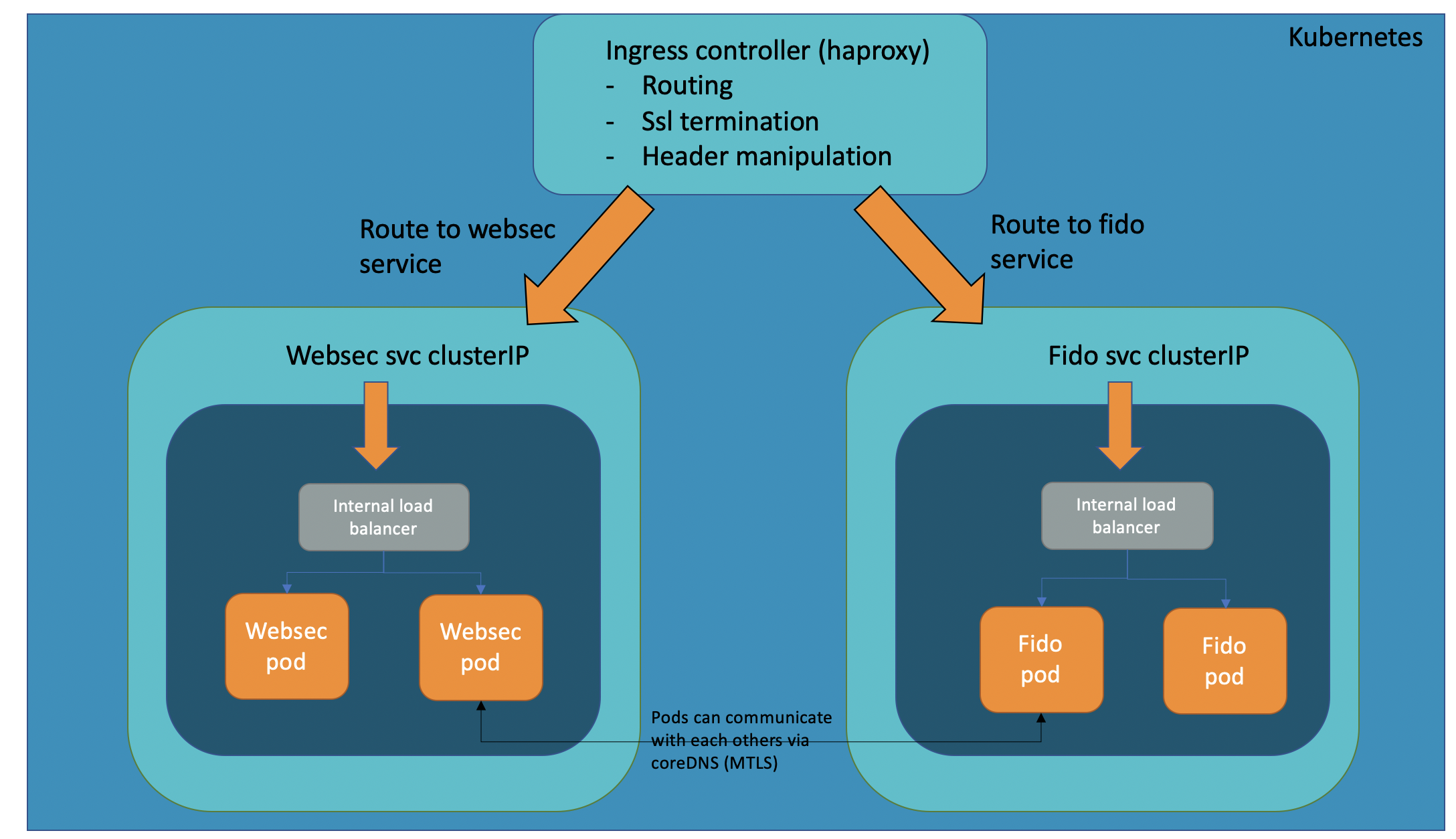
The ingress controller (haproxy) is the main ingress from outside in the cluster. ALL the services in the VID platform are clusterIP, meaning they are not visible from outside, except when an ingress route is available. Any service is not available directly from outside, it must be reachable and expose via routes (sni or ports) in the haproxy. The ingress controller is deployed as a daemonset k8s resource, meaning that will contain a pod on each node. All the services are clusterIPs, splitted in two groups:
services based on deployments
services based on statefullsets
Services based on deployments are the webapp microservices (websec, websecadmin, adservice, fido, statistics, opa, notifications, dmz, shiboleth and selfservice) and persistence microservices (data-retention), while services based on statefullsets are the persistence layer(cassandra, kafka, zookeeper).
The deployments are easily scalable based on load, meaning we can use HPA (Horizontal pod autoscalers) to easily scale replicas based on processor usage. Statefullset are stable based on mounting an external volume gp2 (EBS or other type of disk, different from ephemeral storage or localpath).
An internal look of service ClusterIP with its internal load balancer (in the below schema, replicasets are ignored).
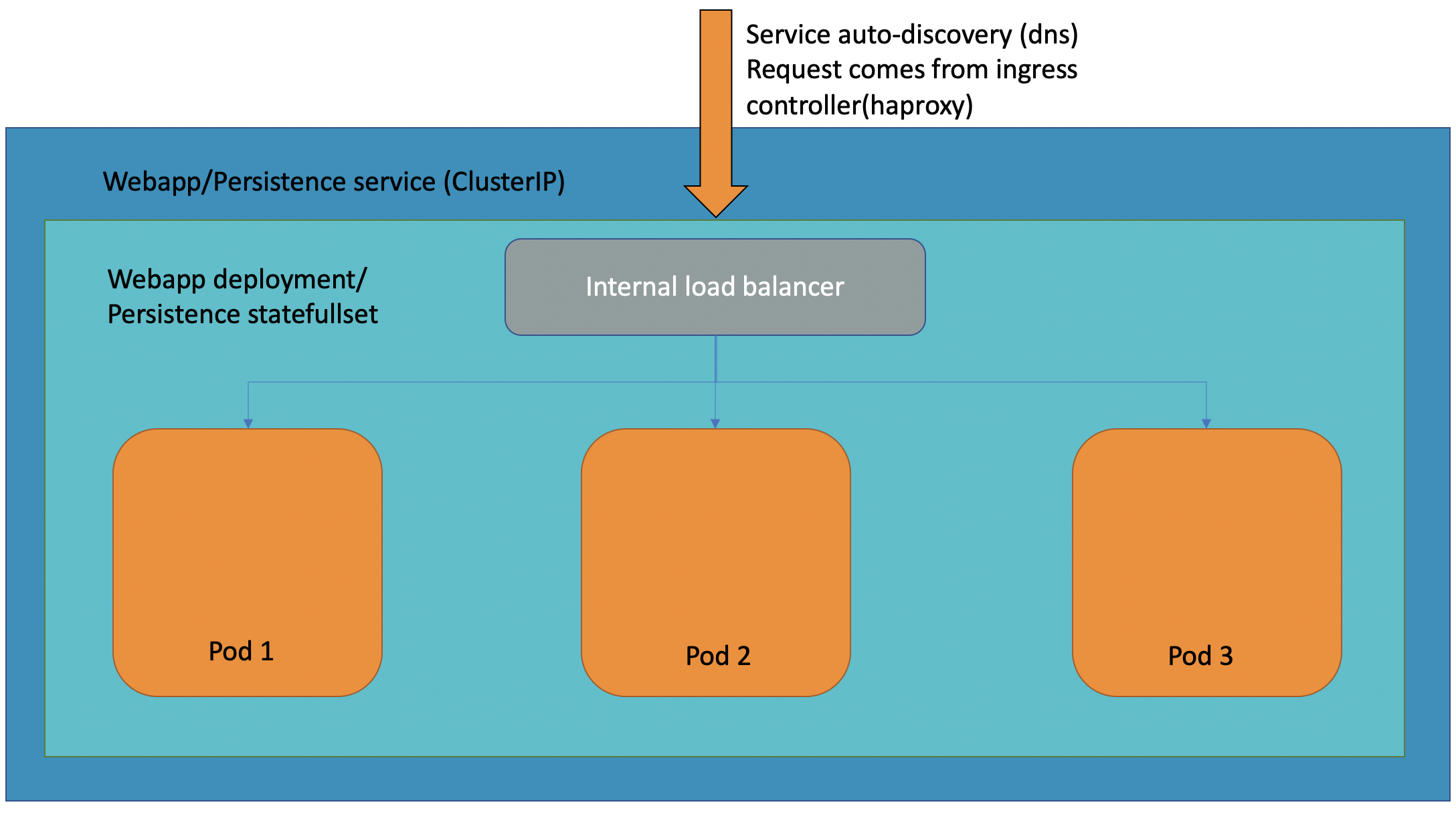
Requests are first routed in the ingress controller based on the routes (sni or ports) to the service, where the internal load balancer from the deployment or statefullset routes the traffic to one of its pod.
The reduce the number of deliverables artefacts, the application code will still use RPMs as main packaging option.